
【SD閱讀筆記】02 - Martin Kleppmann 談分散式鎖:Redlock 真的安全嗎?

重讀 Martin Kleppmann 經典文章,探討分散式鎖的 Efficiency vs Correctness 場景區分,以及為什麼 Redlock 在正確性要求下並不安全
最近重讀了 Martin Kleppmann 在 2016 年發表的經典文章 《How to do distributed locking》。這篇文章雖然起因於對 Redis 作者 antirez 所提出的 Redlock 演算法的質疑,但其價值遠超出了這場辯論本身。文中探討了兩個核心觀念
- 我們究竟為什麼需要鎖?
- 時間在分散式系統中的不可靠性
在 System Design 中是極具價值的決策依據,甚至可以說是分散式系統設計的基礎安全守則
通常在設計系統的時候遇到有 race condition 風險的地方,會直覺的加上 lock,而多數系統會採用 redis 作為分散式鎖的來源,甚至現在使用 AI 工具幫我產生 scaffold 的時候還會自動幫我採用 Redlock,重讀完這篇文章後可以重新審視這個決策以及對技術選型的思考
回歸原點:What are you using that lock for?
在深入演算法細節前,Martin 強調了一個常被忽略的前提:你引入鎖的目的是什麼? Martin 提出了會想要使用鎖的情況
- Efficiency:你的目標是避免重複做同樣的工作以節省資源
- 例子:
- 訊息重複:由於MQ的
at-least-once特性導致處理一次就好的任務被多次處理 (暫不考慮冪等的問題),例如廣告信、一些通知訊息等 - 昂貴運算:例如每天要花兩小時生成的報表被執行兩次,純浪費 CPU 跟 IO 資源
- 緩存擊穿:避免大量請求同時打到資料庫去重建同一個 Cache Key
- 訊息重複:由於MQ的
- 代價:如果兩個 client 同時拿到了鎖,通常可能帳單多了一點零頭、使用者收到兩封一樣的廣告信件,不會造成結構性的破壞
- 選型:單機 Redis、Redis Cluster (即便偶爾掉資料也沒關係)
- 例子:
- Correctness:目標是防止併發的 process 互相干擾,確保系統狀態一致。在這裡,鎖是系統正確性的基石,沒有一點妥協的空間
- 例子:
- 檔案系統:防止兩個 writer 同時寫入同一個檔案,導致內容交錯損毀
- 金融交易:銀行轉帳時,確保餘額扣款的原子性
- 醫療與物流:防止醫療設備重複給藥,或演唱會門票的 Double Booking
- 代價:如果鎖失效了,後果是災難性的。資料一旦損毀或覆蓋,可能導致無法挽回的財務損失、法律責任,甚至在物理世界造成傷害
- 選型:這正是 Redlock 爭議的核心,整個 Redlock 依靠一個適當長度的TTL跟正確的時鐘作為基本假設,但現實中並不保證這個假設永遠為真
- 例子:
隱形殺手
Case I:客戶端的 Zombie Worker
文章中第一個問題是關於 Process Pauses 的探討,常見的情境就是 JVM GC 的 Stop The World
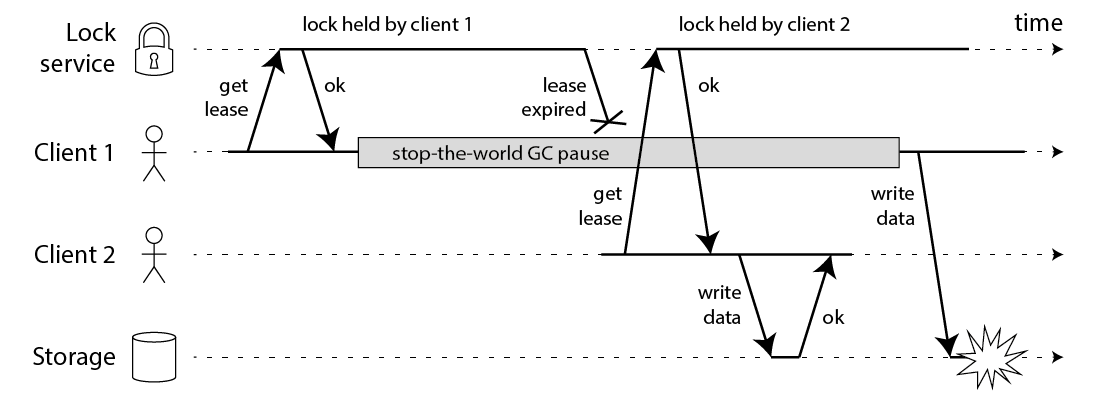
我們一般假設拿到鎖之後,程式會正常在鎖過期前執行完畢。但在真實的分散式環境中,這個假設十分不可靠。Martin 舉了一個 Zombie Worker 的場景,揭示了為什麼依賴超時自動釋放的鎖在正確性場景下是不安全的:
- Client 1 成功拿到鎖,準備開始工作
- Client 1 遭遇了意外的停頓。原因可能很多:
- GC (Stop-the-world):對於 JVM,長時間的 GC 暫停是常態
- Page Fault:記憶體被 Swap 到硬碟,讀取時導致執行續阻塞
- VM/Container 遷移:雲端供應商可能會暫停你的 VM 進行熱遷移,這個過程對 Application 是透明的,但時間確實流逝了
- 時間流逝,鎖在 Server 端超過 TTL 自動釋放
- Client 2 趁機拿到鎖,並寫入新的數據(例如將資料庫中的
version從 1 改為 2) - Client 1 終於醒來(Zombie Worker),它不知道自己睡了一覺,記憶體中的變數告訴它「我還持有鎖」,於是它強制寫入數據(將
version1 的舊數據覆蓋上去) - 結果:Client 2 的正確數據被 Client 1 覆蓋,產生了 Race Condition,資料損毀
Case II:伺服器端的時鐘跳躍 (Clock Jump)
除了 Client 端的問題,Redlock 演算法本身依賴於 多數決 (Quorum) 機制 和 節點的本地時間,這在時間不可靠的環境下會成為致命傷
假設我們有一個由 5 個 Redis 節點(A, B, C, D, E)組成的 Redlock 叢集,要取得鎖必須獲得至少 3 個節點的同意
故障重現
- Client 1 請求鎖,成功獲得了節點 A, B, C 的鎖(滿足 3/5 多數),開始執行任務
- 災難發生:節點 C 的系統時鐘發生了 Clock Jump
- 這可能是因為 NTP 伺服器進行校時,將時間突然調整了一大截
- 節點 C 認為 Client 1 的鎖已經過期了,於是刪除了該鎖
- Client 2 發起鎖請求
- 它嘗試獲取鎖,成功拿到了 C, D, E(因為 C 認為自己是自由的)
- Client 2 也滿足了 3/5 多數,認為自己獲得了合法的鎖
- Split Brain:現在,Client 1 認為自己持有鎖,因為它當初達到 quorum,Client 2 也認為自己持有鎖
- 結果:互斥性 (Mutual Exclusion) 被打破,兩個 Client 同時操作共享資源,資料損毀
這個案例凸顯了 Redlock 與 Paxos/Raft 等共識演算法的根本差異:
- Paxos/Raft:safety 來源是 quorum intersection,不依賴 wall clock
- Redlock:依賴物理時間(Wall-clock time)來判斷鎖的有效性,即便不是 clock jump,輕微的 clock drift 或網路延遲也足以破壞 Redlock 的安全假設。只要物理時鐘不可靠,Redlock 的安全性就不可靠
解法:Fencing Token
既然鎖會過期,客戶端會暫停,系統時鐘會跳躍,那麼單靠鎖本身是無法保證互斥的。Martin 提出了一個必要的機制:Fencing Token
這需要鎖與 Storage 的配合,這也是一種從 Locking 轉向 Versioning 的思維範式轉移:
- 鎖服務 (Lock Service):當 Client 取得鎖時,服務必須回傳一個單調遞增的數字 (例如: Token = 33)
- 儲存層 (Storage):Client 寫入資料時,必須帶上這個 Token。Storage 會記錄下最後處理的 Token
- 如果收到的 Token (33) 大於 目前記錄的 Token (例如 32),則接受寫入,並更新記錄為 33
- 如果收到的 Token (33) 小於 目前已經處理過的 Token (例如 34,表示 Client 2 已經寫入過了),Storage 必須拒絕該次寫入
實作範例 (Implementation Example)
假設我們有一個資料表 account_balances,我們希望透過 Fencing Token 來防止過期的寫入
- Schema 設計:在資料表中增加一個欄位
last_fencing_token
ALTER TABLE account_balances ADD COLUMN last_fencing_token BIGINT DEFAULT 0;- Zombie Worker 的攻擊與防禦:
- Client A 拿到了 Token
33,但在執行過程中暫停了,Client B 之後拿到了 Token34並成功寫入 - Client B (正常執行):
UPDATE account_balances
SET balance = 1000, last_fencing_token = 34
WHERE id = 123 AND last_fencing_token < 34;
-- Result: Affected rows = 1 (成功)- Client A (Zombie Worker 甦醒): 它嘗試使用舊的 Token
33進行寫入
UPDATE account_balances
SET balance = 500, last_fencing_token = 33
WHERE id = 123 AND last_fencing_token < 33;
-- Result: Affected rows = 0 (失敗!因為目前的 last_fencing_token 已經是 34 了)透過這種簡單的 SQL WHERE 條件檢查,我們將互斥的責任從不可靠的 Locking Service 轉移到了具備 ACID 特性的 DB 身上
Redlock 的根本問題
讀到這裡你可能會想:既然有了 Fencing Token,Redlock 的時鐘問題不就解決了嗎?但問題在於 Redis/Redlock 並不原生提供單調遞增的 fencing token
Redlock 回傳的只有「是否拿到鎖」和「剩餘有效時間」,沒有一個全局遞增的序號,你當然可以自己在 Redis 之外維護一個遞增計數器,但這就引入了新的問題:
- 如果計數器放在單機 Redis,它本身就是單點故障
- 如果計數器也要做分散式,你又回到了原點
相較之下,ZooKeeper 的 zxid、etcd 的 revision 都是內建的單調遞增序號, 天然適合作為 fencing token
這正是 Martin 批評 Redlock 的核心:它無法提供 fencing 機制, 而沒有 fencing 的分散式鎖,在 Correctness 場景下就是不安全的
Fencing Token vs Optimistic Lock (CAS)
這兩種機制經常被混用,但它們解決的問題不同:
| Fencing Token | Optimistic Lock (CAS) | |
|---|---|---|
| 檢查條件 | WHERE token < new_token |
WHERE version = expected_version |
| 語義 | 拒絕「比我舊」的寫入 | 拒絕「跟我預期不同」的寫入 |
| 解決問題 | Zombie Worker(過期鎖持有者) | Lost Update(讀-改-寫競爭) |
| Token 來源 | Lock Service 發出 | 從 Storage 讀取 |
- Fencing Token 的核心假設是 Token 數字越大,代表越新的鎖持有者。 即使 Zombie Worker 醒來,它手上的 Token 33 永遠小於後來者的 Token 34, 因此會被無條件拒絕——不需要知道當前狀態是什麼
- Optimistic Lock 則是在讀取時記下版本號,寫入時驗證沒有人改過,它保護的是單一 Client 的讀-改-寫原子性,而非跨 Client 的時序問題
實務上,兩者可以組合使用:
- Fencing Token 擋掉 Zombie Worker
- Optimistic Lock 處理同一時間多個合法請求的競爭
System Design 決策樹
基於 Martin 的文章與實務經驗,我思考了幾個 System Design 面試或架構設計時會需要用到 lock 的情境
- YouTube 觀看次數計數器
- 重點需求:彙整觀看次數,減輕 DB 壓力,偶爾少算一點沒關係
- 分類:Efficiency
- 分析:追求極致的效能與低延遲,如果要求絕對正確的數字要就不能採用 Redis 作為 Lock 來源,要使用更可靠的 service (例如 Zookeeper ),但追求 CP 的系統延遲較高,在此情況下是典型的 Over-engineering
- 選型:單機 Redis(可搭配 replica 做高可用),避免在 Redis Cluster 上做鎖
- 熱門演唱會搶票系統
- 重點需求:絕對不能發生 Double Booking
- 分類:Correctness
- 分析:為了可靠性上 ZooKeeper 是個選項,但考慮到演唱會是個十分高併發的場景,ZooKeeper 適合作為 correctness guard,但不適合每次請求都打 ,吞吐量無法支撐高頻操作
- 決策:Redis (擋流量) + Optimistic Lock (正確性保證):Redis 不再承擔鎖的正確性角色,而是作為 rate-limiting / gatekeeper,用 DB 作最終 correctness
- Redis:作為第一層護盾,負責 Efficiency 用以阻擋 99% 的無效請求,保護 DB 不被打掛
- DB (RDBMS):作為第二層,利用
UNIQUE KEY或VERSION欄位 (CAS) 來實現類似 Fencing 的機制 - 實作細節:SQL 語句可以是
UPDATE tickets
SET owner = ?, version = version + 1
WHERE id = ? AND version = ? AND owner IS NULL;- 理由:即便 Redis 鎖因為 GC 失效了,Zombie Worker 試圖執行 SQL 時,會因為資料庫層的
version檢查失敗(Affected Rows = 0)而被擋下,這樣既兼顧了 Redis 的高效能,又利用 DB 的 ACID 守住了最後一道防線
- 分散式任務排程 (底層儲存為 S3/Legacy FS)
- 需求:多個 Worker 修改同一個 S3 文件或存取一個不支援 Transaction 的老舊系統
- 分類:Correctness (且儲存層無法協助 Fencing)
- 決策:必須使用 ZooKeeper / etcd
- 理由:當你的底層儲存系統比較簡單,例如 S3 的
PUT操作是直接覆蓋,無法幫你做檢查版本後寫入的動作時,lock 成為了唯一的防線。這時必須依賴共識演算法 (Consensus Algorithm) 的 CP 系統,確保在任何時間點只有一個 Worker 能持有鎖,且系統必須足夠穩定以防止 Split Brain,使用 Redlock 在此場景下極其危險
補充:AWS 在 2024 年 8 月已推出 S3 Conditional Writes,支援If-None-Match和If-Matchheader,可以實現檢查後寫入的語義
總結:除了「鎖」,我們還能相信什麼?
Martin Kleppmann 這篇文章最精彩之處在於他揭示了分散式系統設計中我們可能不經意忽略的前提:我們習慣依賴的時間與順序,可能從前提就錯誤導致後面的結論都不穩固
讀完這篇文章後,我得到的結論是在做 System Design 時不該盲目迷信分散式鎖,而需要進行兩層思考:
- 思考代價:如果鎖失效了,是運維團隊的麻煩 (Efficiency),還是法務團隊的麻煩 (Correctness)?如果是後者,請預設鎖一定會失效
- 尋找 Source of Truth:不要把正確性完全賭在一個依賴時間的外部系統上,只要可以就讓你的 Database/Storage 成為 Source of Truth。Fencing Token 的本質,其實就是承認無法控制時間,因此轉而控制因果順序
技術選型從來沒有標準答案,只有 Trade-off,Redis 依然是處理高併發效率問題的神器,但在面對資料一致性的絕對要求時,唯一可靠的只有遞增的版本號
![【SD閱讀筆記】01 - [Wix] Scaling to 100M:當快取變成毒藥?打破 Cache 迷思](https://images.unsplash.com/photo-1537145752474-249a534bfdea?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDEyfHxjYWNoZXxlbnwwfHx8fDE3NjQ3NjkxNDR8MA&ixlib=rb-4.1.0&q=80&w=750)
Comments ()